c-programming-chap6
Get into a rut early: Do the same processes the same way. Accumulate idioms. Standardize. The only difference (!) between Shakespeare and you was the size of his idiom list - not the size of his vocabulary. [1]
数组
到目前为止,我们所见的变量都只是标量(scalar):标量具有保存单一数据项的能力。
C 语言也支持聚合(aggregate)变量,这类变量可以存储一组数值。C 语言一共有两种聚合类型:数组(array)和 结构(structure)。
其中,数组是本节的主角。它只能存储相同类型的变量集合。
一维数组
1. 一维数组声明
数组是含有多个数据值的数据结构,并且每个数据具有相同的数据类型。这些数据值称为元素(element)。
最简单的数组是一维数组。一维数组中的每个元素一个接一个的排列。
为了声明数组,需要指明数组元素的类型和数量。
1 | |
数组的元素可以是任意类型,数组的长度可以是任何 (整数)常量表达式 指定。
1 | |
但是不能使用变量(C89)
1 | |
尽管 C99 已经允许这种做法,但是,很多编译器并不完全支持 C99 。
2. 数组下标
对数组取下标(subscripting)或进行索引(indexing):为了取特定的数组元素,可以在写数组名的同时在后面加上一个用方括号围绕的整数值。
数组元素始终从 0 开始,所以长度为 n 的数组元素的索引时 0 ~ n - 1
例如,a 是含有 10 个元素的数组:
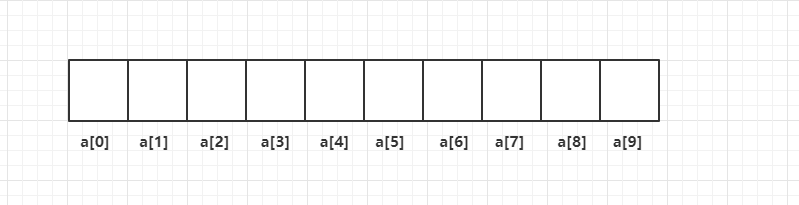
a[i]是左值,所以数组元素可以像不同变量一样使用:
1 | |
3. 数组和 for 循环
许多程序包含的 for 循环都是为了对数组的每个元素执行一些操作。下面给出了长度为 N 的数组 a 的一些常见操作。
1 | |
注意:在调用 scanf 函数读取数组元素时,就像对待普通变量一样,必须使用取地址符号 &
C 语言不要求检查下标的范围。当下标超出范围时,程序可能执行不可预知的行为。
数组下标可以是任何整数表达式:
1 | |
下标可以自增自减:
1 | |
i = 0 时进入循环,打印 a[0] 后 i 的值增加 1 ,这样不断重复;当 i = N - 1 时,打印 a[N - 1] 然后 i 的值加 1 变为 N 不满足 控制表达式 退出循环。
4. 数组初始化
数组初始化(array initializer)
一般的初始化方法:
1 | |
如果初始化式子比数组短,那么剩余的元素被赋值为 0
1 | |
利用这一特性,可以很容易的将数组全部初始化为 0:
1 | |
如果给定了数组的初始化式,可以省略数组长度:
1 | |
编译器利用初始化式的长度来确定数组大小。数组仍有固定数量的元素。
程序示例
示例1. 要求录入一串数据,然后按反向顺序输出这些数:
1 | |
参考程序:
1 | |
这个程序使用宏的思想可以借鉴。
示例2. 数组来处理求Fibonacci数列问题
1 | |
运行结果如下:

示例3.有10个地区的面积,要求对它们按由小到大的顺序排列
💥 ❗️ ❗ 涉及到冒泡排序法
1 | |
运行结果如下:

示例4. 检查数中重复出现的元素[自学]
检查数中是否有出现多于 1 次的数字。
1 )判断是否存在重复出现的数字。
2)输出所有重复出现的数字。
参考答案:
1)
1 | |
2)
1 | |
对于第一个程序,如果你的编译器不支持头 <stdbool.h>,你可以自己定义宏,这个我们之前说过。或者就用 0 1 也可以。
示例5. 计算利息[自学]
编写一个程序显示一个表格。这个表格显示了几年时间内 100 美元投资在不同利率下的价值。用户输入利率和要投资的年数。投资总价值一年算一次,表格将显示输入的利率和紧随其后的 4 个更高的利率下投资的总价值。程序会话如下:
1 | |
第一行用一个 for 语句来显示。
我们在计算第一年的价值的时候将结果存放到数组中,然后使用数组中的结果继续计算下一年的价值。
在这一过程中我们将需要两个 for 语句,一个控制年份,一个控制不同的利率。
程序示例:
1 | |
多维数组
数组可以有任意维数。不过多维数组我们一般只使用二维数组。
1. 二维数组的声明:
1 | |
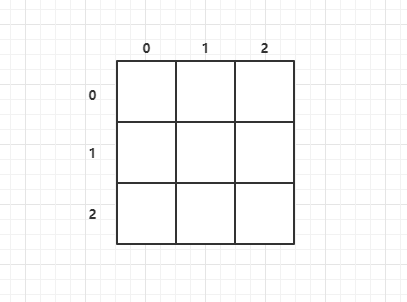
a[i][j]访问的时 第 i 行 第 j 列的元素。
虽然我们以表格的形式显示二维数组,但是实际上它们在计算机的内存中是按照行主序线性存储的,也就是从第 0 行开始。
所以上面的数组实际是这样存储的:
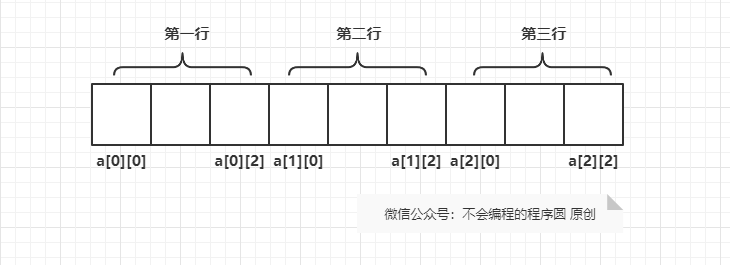
基于这个特性,我们一般用嵌套的 for 循环遍历二维数组:
以下为遍历二维数组的基本操作:
1 | |
2. 二维数组初始化
嵌套的一维数组初始化式:
1 | |
缺省:
1 | |
我们只初始化了第 1 行第 1 个元素,第 2 行第 1,2 个元素,其余的元素初始化为 0
甚至可以不写内层的大括号:
1 | |
一旦编译器填满一行,就开始填充下一行。
试思考,如果这样初始化二维数组,结果会是怎样:
1 | |
第一行被初始化为 1,2,3 其余都为 0
C99 的指定初始化对多维数组也有效。例如:
1 | |
像通常一样,没有指定值的元素默认置 0
多维数组的初始化可以省去第一维(二位数组中的行),其他维度不能省略。
1 | |
二维数组应用举例
- 将一个二维数组行和列的元素互换,存到另一个二维数组中。
1 | |
- 有一个3×4的矩阵,要求编程序求出其中值最大的那个元素的值,以及其所在的行号和列号。
1 | |
3. 多维数组
1 | |
float a[2, 3, 4];在内存中的排列顺序为:
a[0][0][0] → a[0][0][1] → a[0][0][2] → a[0][0][3] → a[0][1][0] → a[0][1][1] → a[0][1][2] → a[0][1][3] → a[0][2][0] → a[0][2][1] → a[0][2][2] → a[0][2][3] → a[1][0][0] → a[1][0][1] → a[1][0][2] → a[1][0][3] → a[1][1][0] → a[1][1][1] → a[1][1][2] → a[1][1][3] → a[1][2][0] → a[1][2][1] → a[1][2][2] → a[1][2][3]
💥 ❗️ ❗ 多维数组元素在内存中的排列顺序为: 第1维的下标变化最慢,最右边的下标变化最快
字符数组
1. 字符数组
用来存放字符的数组称为字符数组,例如:
1 | |
💥 ❗️ ❗ 字符数组实际上是一系列字符的集合,也就是字符串(String)。在C语言中,没有专门的字符串变量,没有string类型,通常就用一个字符数组来存放一个字符串。
C语言规定,可以将字符串直接赋值给字符数组,例如:
1 | |
数组第 0 个元素为’c’,第 1 个元素为’.‘,第 2 个元素为’b’,后面的元素以此类推。
为了方便,你也可以不指定数组长度,从而写作:
1 | |
给字符数组赋值时,我们通常使用这种写法,将字符串一次性地赋值(可以指明数组长度,也可以不指明),而不是一个字符一个字符地赋值,那样做太麻烦了。
💥 ❗️ ❗ 天坑
这里需要留意一个坑,字符数组只有在定义时才能将整个字符串一次性地赋值给它,一旦定义完了,就只能一个字符一个字符地赋值了。请看下面的例子:
1 | |
2. 字符串结束标志[划重点]
字符串是一系列连续的字符的组合,要想在内存中定位一个字符串,除了要知道它的开头,还要知道它的结尾。找到字符串的开头很容易,知道它的名字(字符数组名或者字符串名)就可以;然而,如何找到字符串的结尾呢?C语言的解决方案有点奇妙,或者说有点奇葩。
在C语言中,字符串总是以
'\0'作为结尾,所以'\0'也被称为字符串结束标志,或者字符串结束符。
'\0'是 ASCII 码表中的第 0 个字符,英文称为 NUL,中文称为“空字符”。该字符既不能显示,也没有控制功能,输出该字符不会有任何效果,它在C语言中唯一的作用就是作为字符串结束标志。
C语言在处理字符串时,会从前往后逐个扫描字符,一旦遇到'\0'就认为到达了字符串的末尾,就结束处理。'\0'至关重要,没有'\0'就意味着永远也到达不了字符串的结尾。
由" "包围的字符串会自动在末尾添加'\0'。例如,"abc123"从表面看起来只包含了 6 个字符,其实不然,C语言会在最后隐式地添加一个'\0',这个过程是在后台默默地进行的,所以我们感受不到。
字符串存储示例:
下图演示了"C program"在内存中的存储情形:

注意天坑
需要注意的是,逐个字符地给数组赋值并不会自动添加'\0',例如:
1 | |
数组 str 的长度为 3,而不是 4,因为最后没有
'\0'。
当用字符数组存储字符串时,要特别注意'\0',要为'\0'留个位置;这意味着,字符数组的长度至少要比字符串的长度大 1。请看下面的例子:
1 | |
"abc123"看起来只包含了 6 个字符,我们却将 str 的长度定义为 7,就是为了能够容纳最后的’\0’。如果将 str 的长度定义为 6,它就无法容纳'\0'了。
当字符串长度大于数组长度时,有些较老或者不严格的编译器并不会报错,甚至连警告都没有,这就为以后的错误埋下了伏笔,读者自己要多多注意。
3. 字符数组的输入输出
字符串的输出
在C语言中,有两个函数可以在控制台(显示器)上输出字符串,它们分别是:
- puts():输出字符串并自动换行,该函数只能输出字符串。
- printf():通过格式控制符%s输出字符串,不能自动换行。除了字符串,printf() 还能输出其他类型的数据。
1 | |
注意,输出字符串时只需要给出名字,不能带后边的[ ],例如,下面的两种写法都是错误的:
1 | |
💥 ❗️ ❗ 字符串的输出注意
(1) 输出的字符中不包括结束符
′\0′。
(2) 用“%s”格式符输出字符串时,printf函数中的输出项是字符数组名,而不是数组元素名。
(3) 如果数组长度大于字符串的实际长度,也只输出到遇′\0′结束,即遇到空就结束。
(4) 如果一个字符数组中包含一个以上′\0′,则遇第一个′\0′时输出就结束。
字符串的输入
在C语言中,有两个函数可以让用户从键盘上输入字符串,它们分别是:
scanf():通过格式控制符%s输入字符串。除了字符串,scanf()还能输入其他类型的数据。gets():直接输入字符串,并且只能输入字符串。
但是,scanf() 和 gets() 是有区别的:
scanf()读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串,只能读取一个单词。gets()认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对gets()来说就是一个完整的字符串。换句话说,gets()用来读取一整行字符串。
示例代码:
1 | |
运行结果:
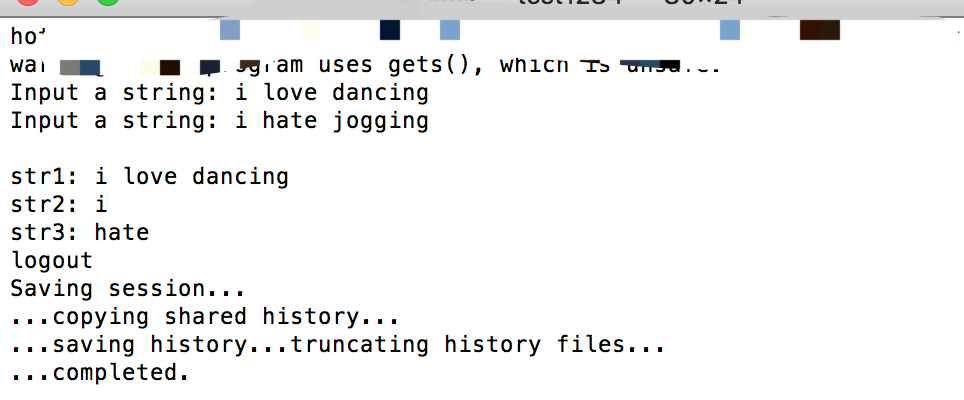
第一次输入的字符串被 gets() 全部读取,并存入 str1 中。第二次输入的字符串,前半部分被第一个 scanf() 读取并存入 str2 中,后半部分被第二个 scanf() 读取并存入 str3 中。
注意
scanf() 在读取数据时需要的是数据的地址,这一点是恒定不变的,所以对于 int、char、float 等类型的变量都要在前边添加&以获取它们的地址。
但是在本段代码中,我们只给出了字符串的名字,却没有在前边添加&,这是为什么呢?因为字符串名字或者数组名字在使用的过程中一般都会转换为地址,所以再添加&就是多此一举,甚至会导致错误了。
就目前学到的知识而言,int、char、float 等类型的变量用于 scanf() 时都要在前面添加&,而数组或者字符串用于 scanf() 时不用添加&,它们本身就会转换为地址。大家一定要谨记这一点。
其他字符串处理函数
字符串连接函数 strcat()
strcat 是 string catenate 的缩写,意思是把两个字符串拼接在一起,语法格式为:
1 | |
strcat() 将把 arrayName2 连接到 arrayName1 后面,并删除原来 arrayName1 最后的结束标志’\0’。这意味着,arrayName1 必须足够长,要能够同时容纳 arrayName1 和 arrayName2,否则会越界(超出范围)。
strcat() 的返回值为 arrayName1 的地址。
下面是一个简单的演示:
1 | |
运行结果:
1 | |
字符串复制函数 strcpy()
strcpy 是 string copy 的缩写,意思是字符串复制,也即将字符串从一个地方复制到另外一个地方,语法格式为:
1 | |
strcpy()会把 arrayName2 中的字符串拷贝到 arrayName1 中,字符串结束标志’\0’也一同拷贝。
请看下面的例子:
1 | |
运行结果:
1 | |
函数将 str2 复制到 str1 后,str1 中原来的内容就被覆盖了。
另外,strcpy() 要求 arrayName1 要有足够的长度,否则不能全部装入所拷贝的字符串。
字符串比较函数 strcmp()
strcmp是 string compare 的缩写,意思是字符串比较,语法格式为:
1 | |
字符本身没有大小之分,strcmp() 以各个字符对应的 ASCII 码值进行比较。strcmp() 从两个字符串的第 0 个字符开始比较,如果它们相等,就继续比较下一个字符,直到出现不同的字符或遇到′\0′为止。
💥 ❗️ ❗ 返回值: 若 arrayName1 和 arrayName2 相同,则返回0;若 arrayName1 大于 arrayName2,则返回大于 0 的值;若 arrayName1 小于 arrayName2,则返回小于0 的值。
对4组字符串进行比较:
1 | |
运行结果:
1 | |
对两个字符串比较不能直接用arrayName1>arrayName2进行比较,因为arrayName1和arrayName2代表地址而不代表数组中全部元素,而只能用 (strcmp(arrayName1,arrayName2)>0)实现,系统分别找到两个字符数组的第一个元素,然后顺序比较数组中各个元素的值。
测字符串长度的函数 strlen()
strlen 是string length的缩写,strlen() 是字符串长度的函数。函数的返回值为字符串中的实际长度(不包括′\0′在内)。
1 | |
转换为大小写的函数
-
strlwr是string lowercase的缩写- 作用:将字符串中大写字母换成小写字母。
-
strupr是string upercase的缩写- 作用:将字符串中小写字母换成大写字母。
以上介绍了常用的8种字符串处理函数,它们属于库函数。库函数并非C语言本身的组成部分,而是C语言编译系统为方便用户使用而提供的公共函数。不同的编译系统提供的函数数量和函数名、函数功能都不尽相同,使用时要小心,必要时查一下库函数手册。
在使用字符串处理函数时,应当在程序文件的开头用#include <string.h>把string.h文件包含到本文件中。
例题 输入一行字符,统计其中有多少个单词,单词之间用空格分隔开。
1 | |
示例代码:
1 | |
参考资料:《C Primer Plus》《C语言程序设计:现代方法》
- 早立规矩:同样方式做的同样处理。积累固定用法(idiom)。标准化。你和莎士比亚的唯一区别是成语(idiom)量——不是词汇量 Epigrams on Programming 编程警句 ↩
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!